
modelscope-funasr的docker版本什么时候更新啊?
ModelscopeFunasr Docker版本更新计划 (图片来源网络,侵删) 当前版本信息 在讨论更新之前,我们需要明确当前的ModelscopeFunasr Docker版本,请参考官方文档或GitHub仓库......
ModelscopeFunasr Docker版本更新计划 (图片来源网络,侵删) 当前版本信息 在讨论更新之前,我们需要明确当前的ModelscopeFunasr Docker版本,请参考官方文档或GitHub仓库......

modelscopefunasr 命令行工具概述 (图片来源网络,侵删) modelscopefunasr 是一个针对自动语音识别(ASR)的命令行工具,它能够将音频文件转换为文本,该工具通常用于处理......

繁简体识别概述 (图片来源网络,侵删) 在文本处理领域,繁简体识别是一个重要功能,特别是对于中文文本,繁体中文和简体中文是现代中文书写的两种主要形式,它们在字符形......

解决modelscopefunasr的whisper3报错问题,可以按照以下步骤进行排查和处理: (图片来源网络,侵删) 1、检查依赖项是否安装完整 确保已经安装了modelscopefunasr所需的所......

故障排除:modelscopefunasr导出onnx失败 (图片来源网络,侵删) 问题描述 尝试将modelscopefunasr模型导出为ONNX格式,但过程中遇到错误导致失败。 可能的原因和解决方案......

说话人识别是语音处理中的一个重要任务,它的目标是确定给定的语音片段是由哪个说话人发出的,在使用modelscopefunasr进行说话人识别时,如果发现该功能不生效,可能是由于......

Modelscopefunasr支持emotion2vec C++推理,下面是一个详细的单元表格,列出了使用Modelscopefunasr进行emotion2vec C++推理的相关信息: (图片来源网络,侵删) 功能/特性......

小标题 内容 问题描述 用户反馈:modelscopefunasr的docker镜像不是c++版本了。 问题分析 根据用户的反馈,我们可以推测出以下几种可能的原因: 1. Docker镜像更新 modelsc......

Whisper 对音频长度的限制 (图片来源网络,侵删) Whisper 是一个由 OpenAI 开发的开源自动语音识别(ASR)模型,它基于深度学习技术,可以实时将语音转换为文本,在使用 ......

在解决modelscopefunasr的websocket demo报错问题之前,我们需要了解一些背景知识,ModelScope是一个开源的语音识别模型库,提供了多种预训练的语音识别模型,可以用于语音......

模型scopefunasr的可用性分析 (图片来源网络,侵删) 在自然语言处理(NLP)领域,分角色模型是一种重要的技术,用于识别文本中不同实体或概念的角色,模型scopefunasr是一......

ModelScopeFunASR是一个基于深度学习的语音识别模型,其交互方式主要包括以下参数: (图片来源网络,侵删) 1、音频文件路径:用于指定待处理的音频文件路径。 2、采样率:......

如何查看运行日志 (图片来源网络,侵删) 在运行模型时,查看运行日志是非常重要的,它可以帮助开发者了解模型的运行状态,找出可能存在的问题,并进行相应的调试,对于Fu......

在ModelScopeFunasr中,麦克风可以直接接上进行实时语音测试,下面将详细介绍如何进行实时语音测试以及相关的注意事项。 (图片来源网络,侵删) 1. 准备设备 在进行实时语......

问题描述: (图片来源网络,侵删) 在使用modelscopefunasr进行微调时,遇到了一个问题,具体问题是在训练过程中,模型的准确率没有明显提升,或者出现了其他异常情况。 解......
 raksmart机房,独立服务器$30/月,香港/台湾/韩国/日本/美国,GPU/多C段站群/150G高防/单机40Gbps带宽,不限流量
2024-12-14
raksmart机房,独立服务器$30/月,香港/台湾/韩国/日本/美国,GPU/多C段站群/150G高防/单机40Gbps带宽,不限流量
2024-12-14 本站同款:拥有1000GB以上DDOS防护(TCP UDP) CC自动防御切换(拦截99%恶意请求)
2024-12-14
本站同款:拥有1000GB以上DDOS防护(TCP UDP) CC自动防御切换(拦截99%恶意请求)
2024-12-14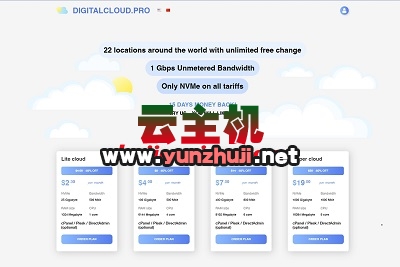 digitalcloud:全球24个机房(美国/香港/新加坡等),不限流量(1Gbps带宽),低至$2.3/月,1G内存/1核/25gNVMe
2024-12-14
digitalcloud:全球24个机房(美国/香港/新加坡等),不限流量(1Gbps带宽),低至$2.3/月,1G内存/1核/25gNVMe
2024-12-14 justhost:8元/月起,每个VPS可免费一键切换IP/机房(50次),不限流量,香港/新加坡/美国/俄罗斯等35个数据中心
2024-12-14
justhost:8元/月起,每个VPS可免费一键切换IP/机房(50次),不限流量,香港/新加坡/美国/俄罗斯等35个数据中心
2024-12-14 UCloud年底上云限时特惠再降一波
2024-12-14
UCloud年底上云限时特惠再降一波
2024-12-14 RackNerd新年促销:美国/爱尔兰便宜VPS,低至$11.29/年1G内存/1核/24gSSD/2T流量/1Gbps带宽2024-12-24
RackNerd新年促销:美国/爱尔兰便宜VPS,低至$11.29/年1G内存/1核/24gSSD/2T流量/1Gbps带宽2024-12-24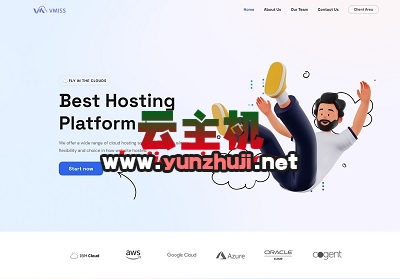 #双诞# vmiss全场VPS低至91元/年,香港VPS-6折优惠,日本/韩国/美国/英国VPS-8折优惠2024-12-24
#双诞# vmiss全场VPS低至91元/年,香港VPS-6折优惠,日本/韩国/美国/英国VPS-8折优惠2024-12-24 V5Net:美国/香港VPS-5折优惠,130元/年,1G内存/1核/30gSSD/500G流量/500Mbps带宽2024-12-29
V5Net:美国/香港VPS-5折优惠,130元/年,1G内存/1核/30gSSD/500G流量/500Mbps带宽2024-12-29 Amazon Bedrock:Claude模型调用享9折优惠!支持免费测试!2024-12-15
Amazon Bedrock:Claude模型调用享9折优惠!支持免费测试!2024-12-15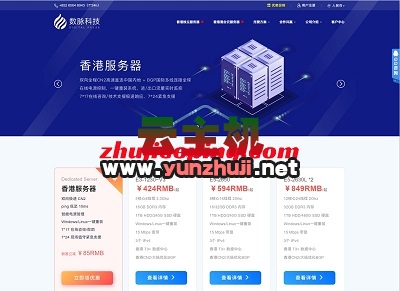 数脉科技:新春特惠,香港独服5折优惠,低至211元/月,e3+30M带宽/不限流量+2个IP2025-01-17
数脉科技:新春特惠,香港独服5折优惠,低至211元/月,e3+30M带宽/不限流量+2个IP2025-01-17
最新评论
本站CDN与莫名CDN同款、亚太CDN、速度还不错,值得推荐。
感谢推荐我们公司产品、有什么活动会第一时间公布!
我在用这类站群服务器、还可以. 用很多年了。