
pig -x mapreduce_MapReduce
MapReduce的基本概念 (图片来源网络,侵删) MapReduce是一种编程模型,用于处理和生成大数据集,它由两个主要阶段组成:Map(映射)和Reduce(归约),这个模型非常适合于......
MapReduce的基本概念 (图片来源网络,侵删) MapReduce是一种编程模型,用于处理和生成大数据集,它由两个主要阶段组成:Map(映射)和Reduce(归约),这个模型非常适合于......

本摘要将介绍如何在CDH集群上使用Maven编写和部署MapReduce作业。我们将讨论配置环境、开发MapReduce代码以及在CDH集群上执行作业的步骤。 在Cloudera Manager(CM)中部署......

CDH5 (Cloudera’s Distribution Including Apache Hadoop) version 5 is a Big Data platform that includes Maven, a software project management and comprehensi......

Parquet Format (图片来源网络,侵删) Parquet是一种列式存储的文件格式,用于高效地存储和处理大量数据,它是由Twitter和Cloudera共同开发,旨在提高大数据处理的性能,......

Copra是一个使用MapReduce模型实现的数据处理框架。它通过将大规模数据集分割成小块,然后并行处理这些块来加快数据分析和处理的速度。Map函数负责数据的映射转换,而Reduc......

Canopy是一个基于Java的MapReduce框架,它提供了一种简化的方式来处理大规模数据。通过将数据处理任务分解为多个小任务,并在多台计算机上并行执行这些任务,Canopy可以显著......

Cloudera CDH5与OBS(对象存储服务)的集成,实现了高效的数据存储和处理。通过执行MapReduce任务,CDH5能够直接读写OBS中的数据,优化了数据处理流程,提高了性能和可扩展......

CDH MapReduce 是一种基于 Cloudera Distribution Hadoop (CDH) 的数据处理框架,用于大规模数据集的并行处理。在 CDH 中部署 MapReduce 需要配置相关服务,如 Yarn、HDFS ......

HDFS是Hadoop Distributed File System的缩写,意为Hadoop分布式文件系统。它是一个高度容错性的系统,设计用来在低成本的硬件上提供高吞吐量的数据访问,适合那些有着超大......

Hive是由Facebook开发的。它是一个数据仓库基础工具,用于处理大规模数据集的存储和分析。Hive建立在Hadoop之上,将SQL查询转换为MapReduce任务,在HDFS中执行,从而允许用......

大数据领域常用的软件包括Hadoop、Spark、Flink等分布式计算框架,以及Hive、Pig、HBase等数据仓库和数据处理工具。还有各种可视化工具如Tableau、Power BI等用于数据分析和......

MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。它通过“映射(Map)”和“归约(Reduce)”将任务分发到多个处理节点,实现高效计算。 MapReduce是一种......

HBase是一个开源的、非关系型、分布式数据库,它是Apache软件基金会的Hadoop项目的一部分。HBase的设计目标是在HDFS之上提供一个大规模结构化存储解决方案,具有高可靠性、......

HDFS(Hadoop Distributed File System)是 Hadoop 项目的一个子项目,用于存储数据,以便运行在通用硬件上的分布式系统。HDFS 命令用于与 HDFS 进行交互,例如创建目录、上......

安装Hadoop前需配置Java环境,下载Hadoop压缩包,解压并设置环境变量,编辑配置文件,然后启动Hadoop服务。 虚拟机安装Hadoop的步骤 在当今大数据时代,Hadoop作为一个开源......
 raksmart机房,独立服务器$30/月,香港/台湾/韩国/日本/美国,GPU/多C段站群/150G高防/单机40Gbps带宽,不限流量
2024-12-14
raksmart机房,独立服务器$30/月,香港/台湾/韩国/日本/美国,GPU/多C段站群/150G高防/单机40Gbps带宽,不限流量
2024-12-14 本站同款:拥有1000GB以上DDOS防护(TCP UDP) CC自动防御切换(拦截99%恶意请求)
2024-12-14
本站同款:拥有1000GB以上DDOS防护(TCP UDP) CC自动防御切换(拦截99%恶意请求)
2024-12-14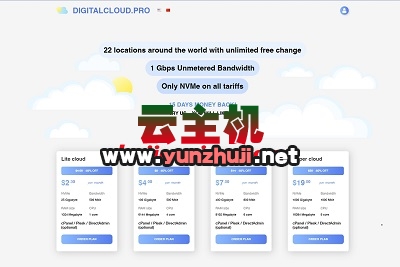 digitalcloud:全球24个机房(美国/香港/新加坡等),不限流量(1Gbps带宽),低至$2.3/月,1G内存/1核/25gNVMe
2024-12-14
digitalcloud:全球24个机房(美国/香港/新加坡等),不限流量(1Gbps带宽),低至$2.3/月,1G内存/1核/25gNVMe
2024-12-14 justhost:8元/月起,每个VPS可免费一键切换IP/机房(50次),不限流量,香港/新加坡/美国/俄罗斯等35个数据中心
2024-12-14
justhost:8元/月起,每个VPS可免费一键切换IP/机房(50次),不限流量,香港/新加坡/美国/俄罗斯等35个数据中心
2024-12-14 UCloud年底上云限时特惠再降一波
2024-12-14
UCloud年底上云限时特惠再降一波
2024-12-14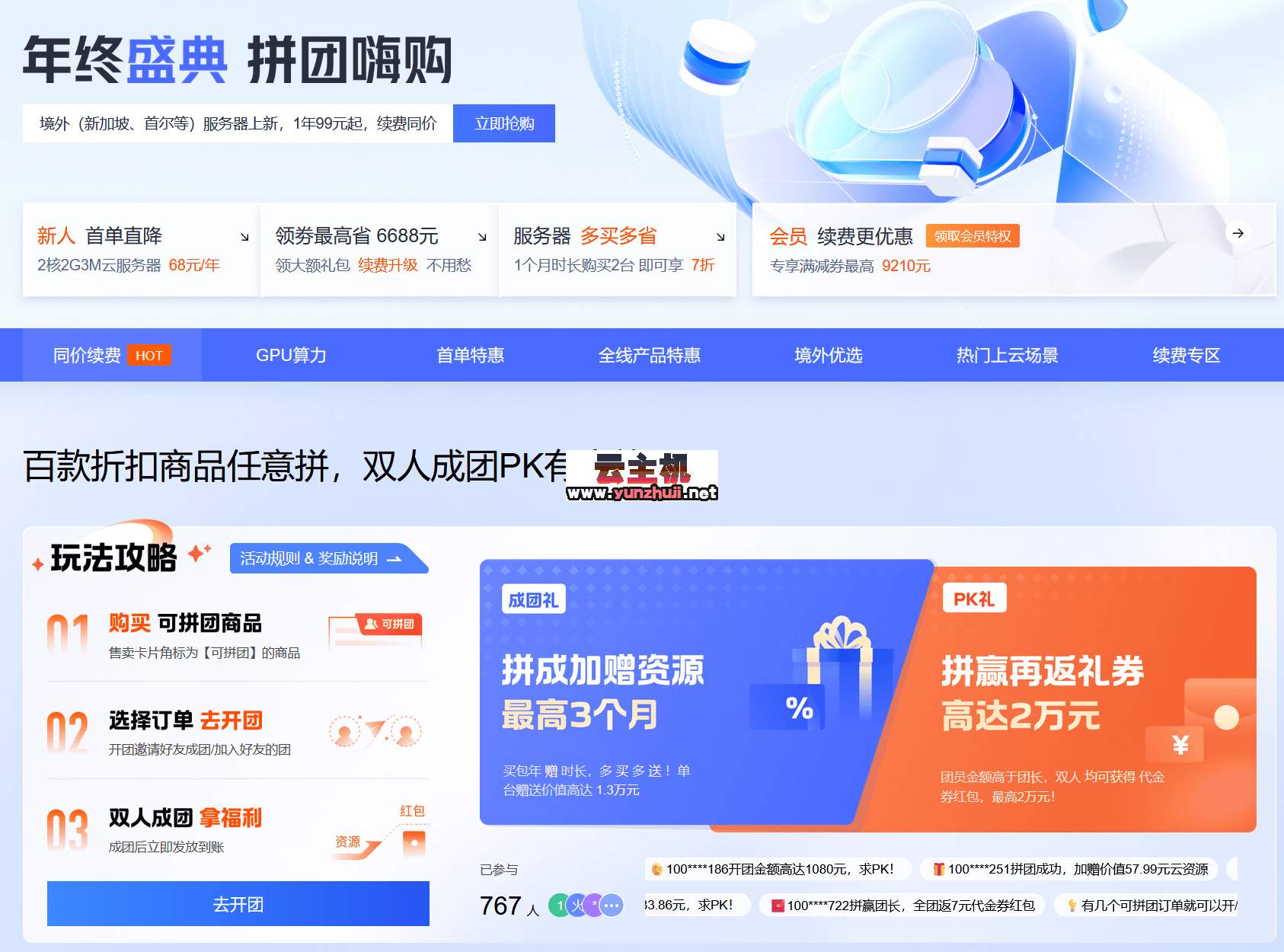 腾讯云年终盛典 拼团嗨购 轻量 2核2G3M低至38元 轻量 4核8G12M=428元 超值优惠!2024-12-14
腾讯云年终盛典 拼团嗨购 轻量 2核2G3M低至38元 轻量 4核8G12M=428元 超值优惠!2024-12-14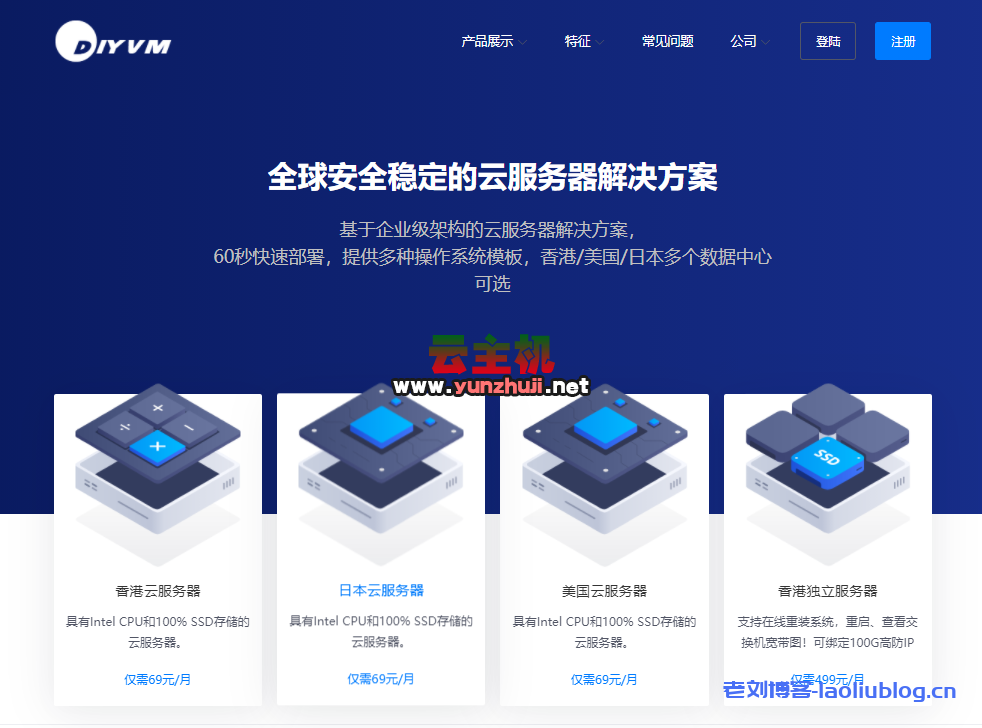 DiyVM:美国CN2/香港CN2不限流量VPS月付50元起,独立服务器月付499元起2024-12-20
DiyVM:美国CN2/香港CN2不限流量VPS月付50元起,独立服务器月付499元起2024-12-20 Amazon Bedrock:Claude模型调用享9折优惠!支持免费测试!2024-12-15
Amazon Bedrock:Claude模型调用享9折优惠!支持免费测试!2024-12-15 cloudcone:2025特价年付美国VPS,$17/年-1G内存/2核/14gSSD/3T流量/1Gbps带宽2025-01-11
cloudcone:2025特价年付美国VPS,$17/年-1G内存/2核/14gSSD/3T流量/1Gbps带宽2025-01-11 iwebfusion:美国独服新年大促/清仓,AMD Ryzen 9 9950X/EPYC 9754等多款机型,低至$45/月2024-12-19
iwebfusion:美国独服新年大促/清仓,AMD Ryzen 9 9950X/EPYC 9754等多款机型,低至$45/月2024-12-19
最新评论
本站CDN与莫名CDN同款、亚太CDN、速度还不错,值得推荐。
感谢推荐我们公司产品、有什么活动会第一时间公布!
我在用这类站群服务器、还可以. 用很多年了。