
模型开发、训练与部署过程中,如何确保模型的高效性与准确性?
模型开发、模型训练和模型部署是机器学习项目中的三个关键步骤。模型训练是指利用数据对模型进行优化的过程。 在当今数据驱动的世界中,机器学习模型已成为许多行业解决复杂......
模型开发、模型训练和模型部署是机器学习项目中的三个关键步骤。模型训练是指利用数据对模型进行优化的过程。 在当今数据驱动的世界中,机器学习模型已成为许多行业解决复杂......

解决神经网络算法中欠拟合的方法可以大致分为几个方向,包括对数据的预处理、模型结构的优化、训练过程中的参数调整等,以下将详细介绍几种有效的解决方法: 1、数据预处理......

在神经网络算法中,欠拟合指的是模型无法从训练数据中学习到足够的特征或模式,导致在新的、未见过的数据上表现不佳,解决欠拟合的方法主要包括数据预处理、调整网络结构、......

解决欠拟合是深度学习模型训练过程中的关键步骤之一,其目的在于提升模型的泛化能力并确保其能够充分捕捉数据的内在模式,面对欠拟合问题,以下是一些解决方法,具体介绍如......

基于Python的机器学习作品展示了端到端的应用场景,从数据预处理、模型训练到结果评估,覆盖了机器学习项目的完整流程。通过实例演示如何运用Python库进行特征工程、模型选......

摘要:本文讨论了Python在机器学习模型开发中的应用,涵盖了从数据预处理到模型部署的端到端场景。文章强调了Python语言的灵活性和丰富的库支持,使得它成为实现机器学习项......

解决神经网络中欠拟合问题的方法包含多种策略,涉及从数据预处理到模型架构的多个方面,具体如下: 1、数据预处理 归一化处理:对数据进行归一化处理可以减少数据间的差异性......

基于Python的机器学习实践指南,涵盖从数据预处理到模型部署的完整流程。内容涉及数据探索、特征工程、模型选择、训练评估及最终的模型部署,旨在为学习者提供一条清晰的端......

命令自动填充_缺失值填充是指在数据处理过程中,通过特定算法或方法,对数据集中的缺失值进行预测、估算并填补,以保持数据的完整性和可用性。 在数据分析中,处理缺失值是......

使用Python调用深度学习模型进行预测通常涉及加载预训练的模型,准备输入数据,通过模型传递这些数据,并获取预测结果。这需要对深度学习库如TensorFlow或PyTorch有基本了解......

在Python中,处理空值或缺失值的常用方法是填充。可以使用pandas库中的fillna()函数来填充缺失值。可以使用特定值、平均值、中位数或前后值进行填充。 在Python中,我们经常......

在Python中,数据清理是一个重要的步骤,可以通过配置数据清理策略来确保数据的质量和准确性。这包括处理缺失值、异常值、重复值等,以及进行数据转换和标准化。 数据清理策......

本文将通过Python机器学习的例子,详细解析端到端场景的实现过程。从数据预处理、模型选择、训练到评估,一步步引导读者理解和掌握端到端机器学习的全过程。 端到端机器学习......

数据准备 1、数据收集:从各种来源(如数据库、API、爬虫等)收集数据。 (图片来源网络,侵删) 2、数据清洗:处理缺失值、异常值、重复值等问题,使数据更加干净和可用。......

在Python中,有许多用于机器学习的库和框架,这些库提供了各种工具和功能,使开发人员能够更容易地构建和部署机器学习模型,以下是一些常用的Python机器学习库: (图片来源......
 raksmart机房,独立服务器$30/月,香港/台湾/韩国/日本/美国,GPU/多C段站群/150G高防/单机40Gbps带宽,不限流量
2024-12-14
raksmart机房,独立服务器$30/月,香港/台湾/韩国/日本/美国,GPU/多C段站群/150G高防/单机40Gbps带宽,不限流量
2024-12-14 本站同款:拥有1000GB以上DDOS防护(TCP UDP) CC自动防御切换(拦截99%恶意请求)
2024-12-14
本站同款:拥有1000GB以上DDOS防护(TCP UDP) CC自动防御切换(拦截99%恶意请求)
2024-12-14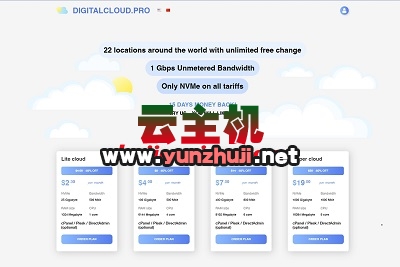 digitalcloud:全球24个机房(美国/香港/新加坡等),不限流量(1Gbps带宽),低至$2.3/月,1G内存/1核/25gNVMe
2024-12-14
digitalcloud:全球24个机房(美国/香港/新加坡等),不限流量(1Gbps带宽),低至$2.3/月,1G内存/1核/25gNVMe
2024-12-14 justhost:8元/月起,每个VPS可免费一键切换IP/机房(50次),不限流量,香港/新加坡/美国/俄罗斯等35个数据中心
2024-12-14
justhost:8元/月起,每个VPS可免费一键切换IP/机房(50次),不限流量,香港/新加坡/美国/俄罗斯等35个数据中心
2024-12-14 UCloud年底上云限时特惠再降一波
2024-12-14
UCloud年底上云限时特惠再降一波
2024-12-14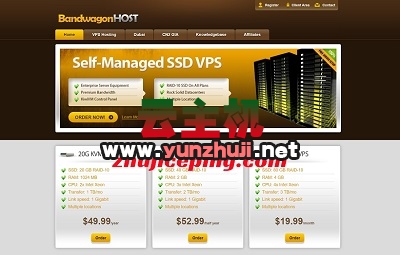 搬瓦工DC99特价VPS:$34.5/年,1G内存/1核/20gSSD/1T流量/1Gbps带宽,三网cn2gia回国2024-12-19
搬瓦工DC99特价VPS:$34.5/年,1G内存/1核/20gSSD/1T流量/1Gbps带宽,三网cn2gia回国2024-12-19 #高速便宜VPS# onetechcloud,低至22元/月,香港CN2/大带宽CMI、美国CN2/CUII/AS4837/高防/双ISP2025-01-17
#高速便宜VPS# onetechcloud,低至22元/月,香港CN2/大带宽CMI、美国CN2/CUII/AS4837/高防/双ISP2025-01-17 微软云Azure:OpenAI GPT服务享9折优惠!支持免费测试!2024-12-19
微软云Azure:OpenAI GPT服务享9折优惠!支持免费测试!2024-12-19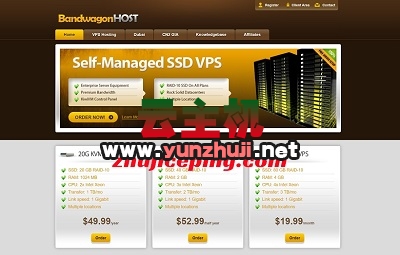 搬瓦工:美国限量款“POWERBOX”VPS,三网cn2gia,$41.95/年-1.5G内存/1核/30gSSD/1.5T流量/2.5Gbps带宽2025-01-05
搬瓦工:美国限量款“POWERBOX”VPS,三网cn2gia,$41.95/年-1.5G内存/1核/30gSSD/1.5T流量/2.5Gbps带宽2025-01-05 #圣诞# rarecloud:VPS低至2.5折,美国/德国/荷兰/罗马尼亚,€8.3/年-1G内存/1核/25gNVMe/3T流量/1Gbps带宽2024-12-25
#圣诞# rarecloud:VPS低至2.5折,美国/德国/荷兰/罗马尼亚,€8.3/年-1G内存/1核/25gNVMe/3T流量/1Gbps带宽2024-12-25
最新评论
本站CDN与莫名CDN同款、亚太CDN、速度还不错,值得推荐。
感谢推荐我们公司产品、有什么活动会第一时间公布!
我在用这类站群服务器、还可以. 用很多年了。