在Python中,我们可以使用Pandas库来解析HTML,Pandas提供了一些方法,如read_html(),可以直接从网页读取表格数据。
以下是一个简单的例子:
import pandas as pd
使用pandas的read_html函数
tables = pd.read_html('http://www.yourwebsite.com')
read_html返回一个列表,其中包含网页上找到的所有表格
for i in range(len(tables)):
print("Table ", i+1)
print(tables[i])
在这个例子中,我们首先导入了pandas库,然后使用read_html()函数从指定的URL读取HTML内容,这个函数会返回一个列表,其中包含了网页上找到的所有表格,然后我们遍历这个列表,打印出每个表格的内容。
注意:你需要将’http://www.yourwebsite.com’替换为你想要解析的实际网址。

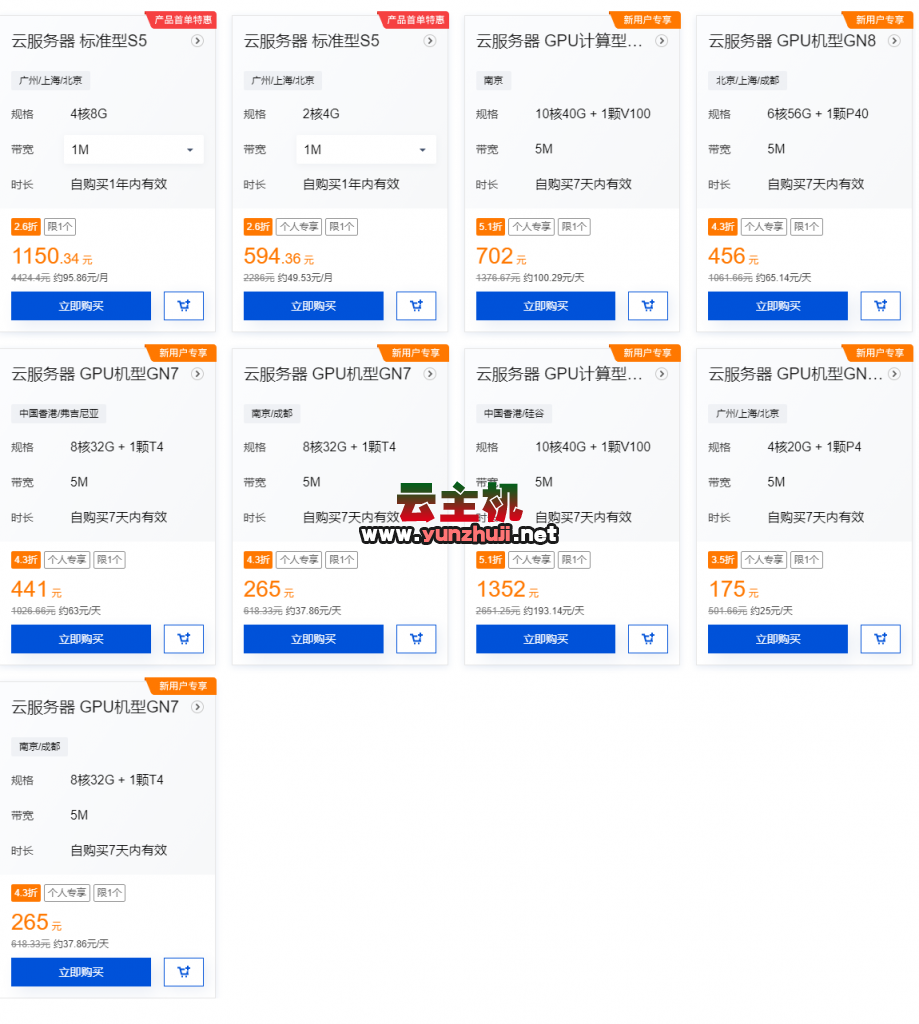











最新评论
本站CDN与莫名CDN同款、亚太CDN、速度还不错,值得推荐。
感谢推荐我们公司产品、有什么活动会第一时间公布!
我在用这类站群服务器、还可以. 用很多年了。