什么是robots文件?
Robots文件,也称为机器人排除协议(Robots Exclusion Protocol),是一种用于告知搜索引擎蜘蛛(也称为爬虫)哪些网页可以抓取,哪些不可以抓取的文本文件,它通常被放置在网站的根目录下,命名为"robots.txt"。
Robots文件的作用和内容
作用:
1、控制搜索引擎蜘蛛对网站的抓取行为:通过设置Robots文件,网站管理员可以限制搜索引擎蜘蛛访问特定页面或目录,以保护敏感信息或优化搜索引擎排名。
2、提高网站性能:限制不必要的抓取可以减少服务器负载,提高网站的响应速度和性能。
3、防止恶意抓取:Robots文件可以阻止恶意爬虫对网站进行大规模的抓取,避免资源浪费和潜在的安全风险。
1、Useragent:指定要控制的搜索引擎蜘蛛的名称,例如Googlebot、Baiduspider等。
2、Disallow:指定不允许抓取的页面或目录路径,可以使用通配符进行匹配。
3、Allow:指定允许抓取的页面或目录路径,可以使用通配符进行匹配。
4、Sitemap:提供网站地图的位置,帮助搜索引擎更好地理解网站结构。
5、Crawldelay:指定搜索引擎蜘蛛在两次访问之间的延迟时间,以减少服务器负载。
6、其他指令:还可以使用其他指令来控制搜索引擎蜘蛛的行为,如指定抓取深度、禁止跟踪链接等。
相关问题与解答:
问题1:为什么有些网站没有robots文件?
答:有些网站可能没有创建robots文件,这可能是因为网站管理员没有意识到其重要性,或者他们希望搜索引擎蜘蛛能够自由地抓取所有页面,在这种情况下,搜索引擎蜘蛛将默认遵循网站的抓取规则。
问题2:如何查看一个网站的robots文件?
答:可以通过在浏览器中输入"site:网站域名/robots.txt"的方式查看一个网站的robots文件,如果要查看百度的robots文件,可以在浏览器中输入"site:baidu.com/robots.txt",请注意,某些网站的robots文件可能无法直接访问,因为它们被设置为私有或需要特定的权限才能查看。
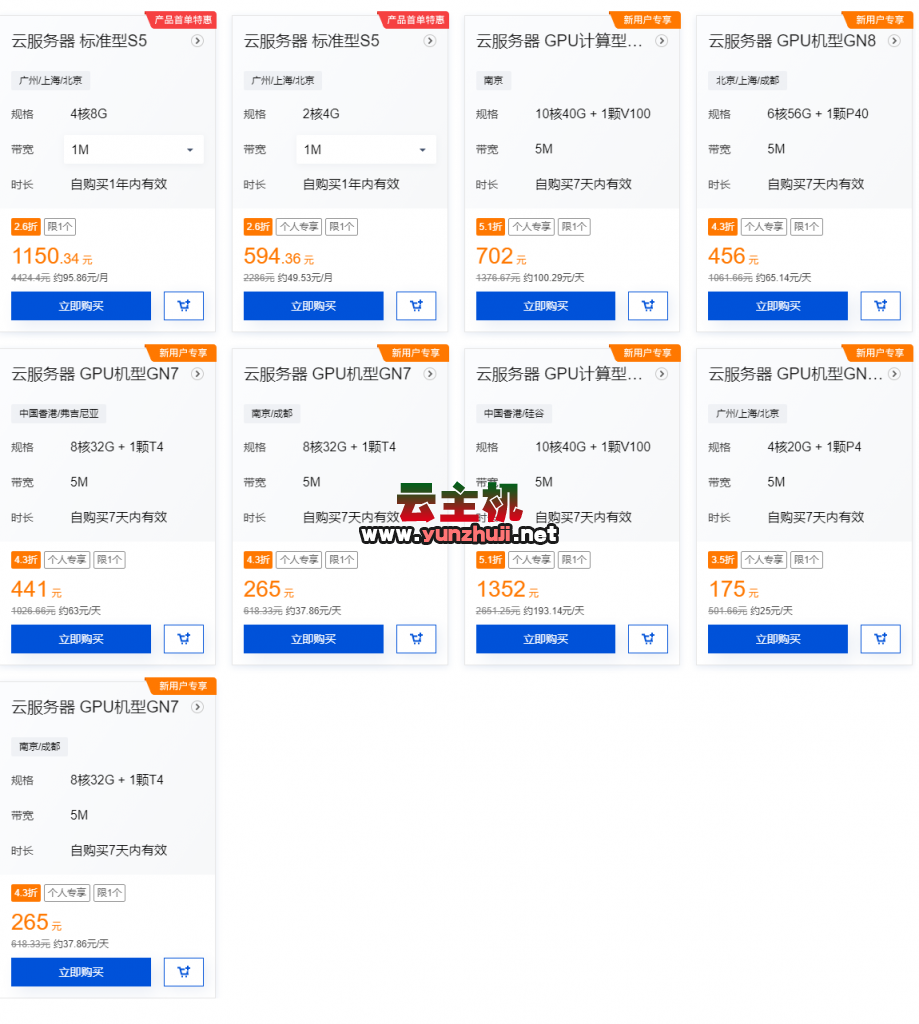










最新评论
本站CDN与莫名CDN同款、亚太CDN、速度还不错,值得推荐。
感谢推荐我们公司产品、有什么活动会第一时间公布!
我在用这类站群服务器、还可以. 用很多年了。